A few weeks ago I stumbled on an excellent video of Greg Young talking at Ordev back in 2010. The topic was object oriented programming and, basically, how I’m an idiot. Not me in particular, it would be somewhat upsetting if Greg had taken the time to do an hour talk on how Simon Timms is an idiot. Upsetting or flattering, I’m not sure which. It is a very worthwhile video and you should make time to watch it. One of the takeaways was about code contracts.

I’ve never given much thought to code contracts before. I was never too impressed by what I considered to be a bunch of noise which tools like Resharper add to your code.
http://gist.github.com/stimms/6133393
“Asserting stuff is all nice and good but it should be caught by unit tests anyway” was my though.I have a lot of respect for Greg so I though I would look into code contracts. I look on them as a sort of extension to interfaces. Interfaces are a programmatic way of describing how an implementation should look. For instance a common interface in the projects I build is ILog which is an interface for logging. It is typically modeled after the ILog interface from Log4Net although it now includes some practices I picked up from my preferred logging framework, NLog.
The compiler guarantees that anything which implements that interface has at least some sort of implementation in place for each one of the defined methods. The compiler doesn’t care what the implementation is so long as there is one there. This allows me to create a “valid” implementation which looks like
This implementation doesn’t actually do what I had intended when I specified the interface. Unfortunately, there is no way, through, interfaces to require that functions actually do what they claim to do. Code contracts add another layer of requirements to implementations and allow for the enforcing of some additional conditions. Having contracts in place allows you to replace many of your unit tests with static checking. Want to ensure that null isn’t passed in? Build a contract. I decided to dig a bit more into how code contracts were working for C#.
As it turns out finding information on code contracts for C# is really difficult. There have been a couple of efforts over the years to bring code contracts into the .net world. The latest and, seemingly, most successful is as part of the PEX project. There was a burst of videos and activity on that project in 2010 but since then activity seem to have fallen off rather dramatically. Most everything in the code contracts works but it is somewhat flaky on visual studio 2012.
To get started you need to install two visual studio extensions: Code Contracts Tools and Code Contracts Editor Extensions VS2012. You can also install the code digger which displays a table of inputs which are checked for your methods. It is useful but is crippleware compared to how it is shown to work in videos like this one. The tool use to have the ability to generate unit tests but as I understand it this functionality is limited to Visual Studio Ultimate. I’m not fabricated from money so I don’t have that. Boo. (well not “Boo” for not being made from money rather “Boo” for the restriction. I’m glad I’m not made from money. Money is filthy)
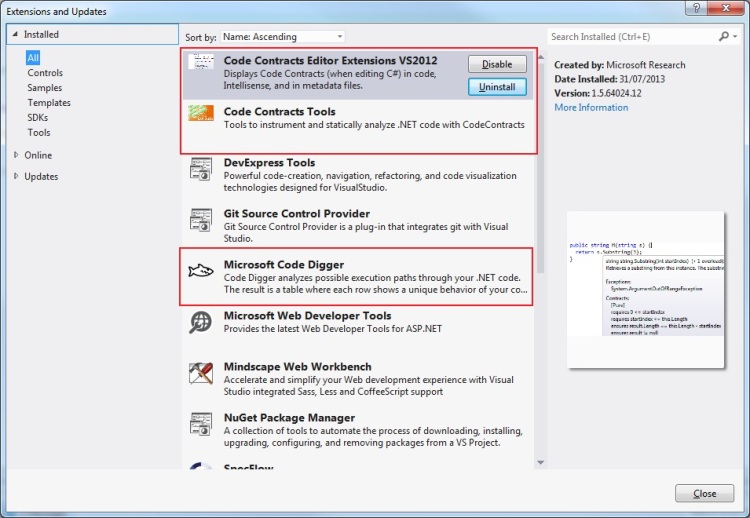
Code contract extensions
Once you have these extensions installed you can start playing around with code contracts. When you come across a method which has contracts attached to it they will be shown in the intellisensehint. Some parts of the .net BCLs have received code contracts treatment. However it is wildly inconsistent which parts have contracts associated with them. Some places where I think they would be useful have been missed and other places are oddly over specified. For instance System.Math:

Missing contracts

Overly complicated contracts
The contracts on Math.Ceiling are pretty obvious yet they don’t seem to have been implemented. Irritating!
If you would like to specify contracts on your own code then, as far as I’m concerned, you should do it at the interface level. Always. You can put contracts on your concrete classes but then you’re all coupled to implementation and that sucks.
Because code contracts are implemented as a library instead of being part of the language syntax like Eiffel you need to set them up in buddy classes next to your interfaces. It is a real shame that they went this way and perhaps, once Rosslyn gets going, there will be a way to modify the language with new key words to deal with contracts.
Let’s say you have a class which does some math, specifically it takes a square root of a number.
This class is an implementation of the IMath interface
Here I’ve added an annotation which points to another class as containing the contracts. I actually really like that the contracts are split out into another class. It keeps the code short and still allows communicating the information about the contracts viaintellisense. The buddy class looks like:
For some reason I don’t really understand you need to specify the class for which it is a contract in an annotation. I think that pollutes the idea of a contract. The implementer should know about what contract it implements but the contract shouldn’t care at all. Each method on which you want a contract is specified and you can put in requires (pre conditions) and ensures (post-conditions). We’ll ignore the existence of i to make a point. The method is never executed so the remainder of the body is not important.
You can try the contract out by attempting to pass in an illegal value.
This will result in errors like

A failing contract
This isn’t very exciting because, of course, -9 is a negative number. Where things get interesting is when you start coupling together contracts.
This will also fail because the contract checker will actually go out and build up a representation of how data moves around the application. It is able to spot the conflicting contracts and warning about them.
The checking won’t actually be run unless you enable it in the properties of your project. I couldn’t find any setting which showedintellisense for the contracts I had created. I believe that is just suppose to work but it didn’t on the machine I used.

Settings for contract checking
If you run into a contract which is failing and you can’t quite figure out what’s going on then the PEX Code Digger can come in handy. You can right click on the method with the contract and it will show you the paths through the method which caused a contract failure. By default it only works on portable class libraries, I understand you can reconfigure that but I don’t know what the repercussions are of that. So I created a portable class library.
Portable Class Library
The System.Diagnostics.Contracts namespace in which the contracts code lives is not part of any of the 4.0 portable subsets. You’ll need to get one of the .net 4.5 portable subsets. That’s not an obvious task. To do it you need to add a brand new library to your project and it needs to use the portable class library template.
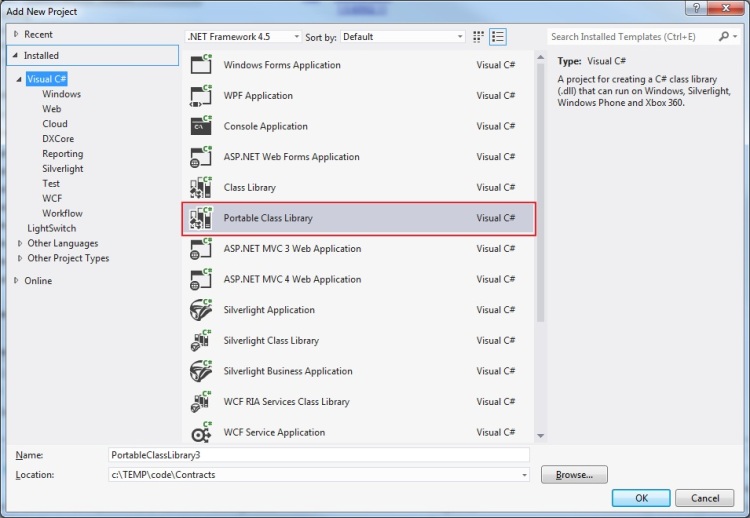
New portable library
You’re then given a choice of platforms. Many of these platforms are not natively .net 4.5 and will result in a 4.0 library. It took some playing around but I found that this combination worked:

Only contract killers on the xbox, no code contracts
Conclusions
I don’t know about contracts. They have the potential to speed up unit testing by creating your tests for you. Well some of your tests. The simple boiler plate tests that everybody skips doing because they’re mind numbing are largely eliminated. Anything which removes a barrier to the adoption of TDD is a good thing in my mind.
However I don’t think the implementation for C# is ready yet. Maybe they’ll never be ready. I asked around a bit but nobody seems to know what happened to code contracts. Are they still being developed? If so where is the activity? How come the editor stuff doesn’t work for my code contracts? Contract checking is also super slow. Even on this small application running the checks took a minute. I cannot imagine what it must do on a large project. Contract checking seems like it might be the sort of thing you run on that build which runs over the weekend. That sort of long feedback cycle is terrible. The better solution is to run the contracts, generate unit tests from them and run the unit tests. However, like I said, that feature seems to have been moved to the elite SKUs.
I won’t be using contracts but I will be keeping an eye out for news of continued work on them.