Earlier this week there was a great blog post over at Hanselman’s blog about what not to do when building an ASP.net website. There was a lot of good advice in there but right at the bottom of the list was the single most important item, in my opinion €Long Running Requests (>110 seconds)€. This means that you shouldn’t be tying up your precious IIS threads with long running processes. Personally I think that 110 seconds is a radically long time. I think that a number like 5 seconds is probably more reasonable, I would also entertain arguments that 5 seconds is too long.
If you look into running recurring tasks on IIS you’re bound to find Jeff Atwood’s article about using cache expiration policy to trigger periodic tasks. As it turns out this is a bad idea. Avoiding long running requests is important for a number of reasons:
There are limited threads available for processing requests. While the number of threads in the app pool is quite large it is possible to exhaust the supply of threads. Long running processes lock up threads for an irregularly long period of time.
The IIS worker process can and does recycle itself every 29 hours. If your background task is running during a recycle it will be reaped.
Web server are just not designed to deal with long running processes, they are designed to rapidly create pages and serve them out.
Fortunately there are some great options for dealing with these sorts of tasks now: queues and separate servers. Virtual servers are dirt cheap now on both Azure and Amazon. Both of these services also have highly robust and scalable queueing infrastructures. If you’re not using the cloud then there are infrastructure based queueing services available too (sorry, I just kind of assume that everybody is using the cloud now).
Sending messages using a queue is highly reliable and extremely easy. To send a message using Azure you have two options: Service Bus and Storage Queues. Choosing between the two technologies can be a bit tricky. There is an excellent article over at Microsoft which describes when to use each one. For the purposes of simply distributing background or long running tasks either technology is perfectly viable. I like the semantics around service bus slightly more than those around storage queues. With storage queues you need to continually poll for new messages. I’m never sure what a polite polling interval is so I tend to err on the side of longer intervals such as 30 seconds. This makes the user experience worse.
Let’s take a look at how we can make use of the service bus. First we’ll need to set up a new service bus instance. In the Azure portal click on the service bus tab.
Now click create
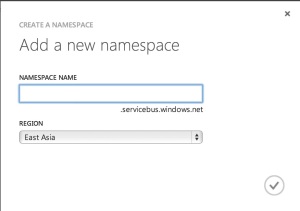 You can enter a name here and also a region. I’ve always figured that I’m closer to West US so it should be the most performant(although I really should benchmark that).
You can enter a name here and also a region. I’ve always figured that I’m closer to West US so it should be the most performant(although I really should benchmark that).
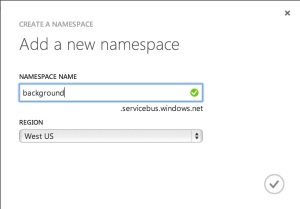 The namespace serves as a container to keep similar services together. Within the namespace we’ll create a queue
The namespace serves as a container to keep similar services together. Within the namespace we’ll create a queue
Once the queue is created it needs to have some shared access policies assigned. I followed the least permission policy and created two policies, one for the web site to write and one for whatever we create to read from the queue.
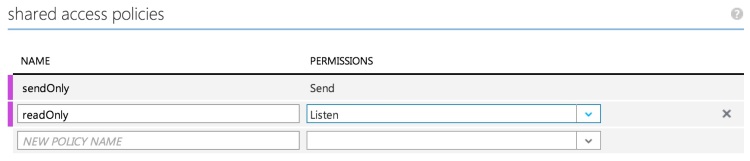
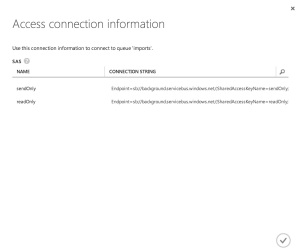
The final task in the console is to grab the connection strings. You’ll need to save the configuration screen and then hop back to the dashboard where there is a handy button for pulling up the connection strings. Take note of the write version of the connection string we’ll be using it in a second. The read version will be later in the article.
 Now we can switch over to Visual Studio and start plugging in the service bus. I created a new web project and selected an MVC project from the options dialog. Next I dropped into the package manager console and installed the service bus tools
Now we can switch over to Visual Studio and start plugging in the service bus. I created a new web project and selected an MVC project from the options dialog. Next I dropped into the package manager console and installed the service bus tools
Install-Package WindowsAzure.ServiceBus
The copied connection string can be dropped into the web.config file. The nuget install actually adds a key into the appSettings and you can hijack that key. I renamed mine because I’m never satisfied(don’t worry I changed the secret in this code).
In the home controller I set up a simple method for dropping a message onto the service bus. One of the differences between the queue and service bus is that the queue only takes a string as a message. Typically you serialize your message and then drop it into a message on the queue. JSON is a popular message format but there are numerous others. With service bus the message must be an instance of a BrokeredMessage. Within that message you can set the body as well as properties on the message. These properties should be considered part of the €envelope€ of the message. It may contain meta-information or really anything which isn’t part of the key business meaning of the message.
This is all it takes to send a message to a queue. Service bus supports topics and subscriptions as well as queues. This mechanism provides for semantics around message distribution to multiple consumers, it isn’t needed for our current scenario but could be fun to explore in the future.
Receiving a message is just about as simple as sending it. For this project let’s just create a little command line utility for consuming messages. In a cloud deployment scenario you might make use of a worker role or a VM for the consumer.
The command line utility needs only read from the queue which can be done like so:
There are a couple of things to note here. The first is that we’re using a tight loop which is typically a bad idea. However the Receive call is actually a blocking call and will wait, for a time, for a message to come in. The wait does time out eventually but you can configure that if needed. I can imagine very few scenarios where changing the default timeout would be of use but others have better imaginations than me.
The second thing to note are the calls to message.Complete and message.Abandon. We’re running the queue in PeekLock mode which means that while we’re consuming the message the read on the queue is blocked. You can still write to the queue but reading is not possible. Once we’ve handled the message we either need to mark it as complete, meaning that the message will be deleted from the queue, or abandoned, meaning that the message will simply be unlocked and available to read again.
That is pretty much all there is to shifting functionality off of the web server and onto a standalone background/long running task server. It is super simple and will typically be a big improvement for your users.
As usual the source code for this is available up on github












