I do all sorts of random work and one of those is helping out on some infrastructure deployments on Azure. Coming from a development background I’m allergic to clicking around inside an Azure website to configure things in a totally non-repeatable way. So I’ve been using Terraform to do the deployments. We have built up a pretty good history of using Terraform - today I might use Pulumi instead but the actual tool isn’t all that important as opposed to the theory.
What I’m looking to achieve is a number of things
- Make deployments easy for people to do
- Make deployments repeatable - we should be able to us the same deployment scripts to set up a dev enviornment or recover from a disaster with minimal effort
- Ensure that changes are reviewed before they are applied
To meet these requirements a build pipeline in GitHub actions (or Azure DevOps, for that matter) is an ideal fit. We maintain our Terraform scripts in a repository. Typically we use one repository per resource group but your needs may vary around that. There isn’t any monetary cost to having multiple repositories but there can be some cognitive load to remembering where the right repository is (more on that later).
Source Code
Changes to the infrastructure definition code are checked into a shared repository. Membership over this code is fairly relaxed. Developers and ops people can all make changes to the code. We strive to make use of normal code review approaches when checking in changes. We’re not super rigorous about changes which are checked in because many of the people checking in changes have ops backgrounds and aren’t all that well versed in the PR process. I want to make this as easy for them as possible so they aren’t tempted to try to make changes directly in Azure.
In my experience there is a very strong temptation for people to abandon rigour when a change is needed at once to address a business need. We need to change a firewall rule - no time to review that let’s just do it. I’m not saying that this is a good thing but it is a reality. Driving people to the Terraform needs to be easy. Having their ad-hoc changes overwritten by a Terraform deploy will also help drive the point home. Stick and carrot.
Builds
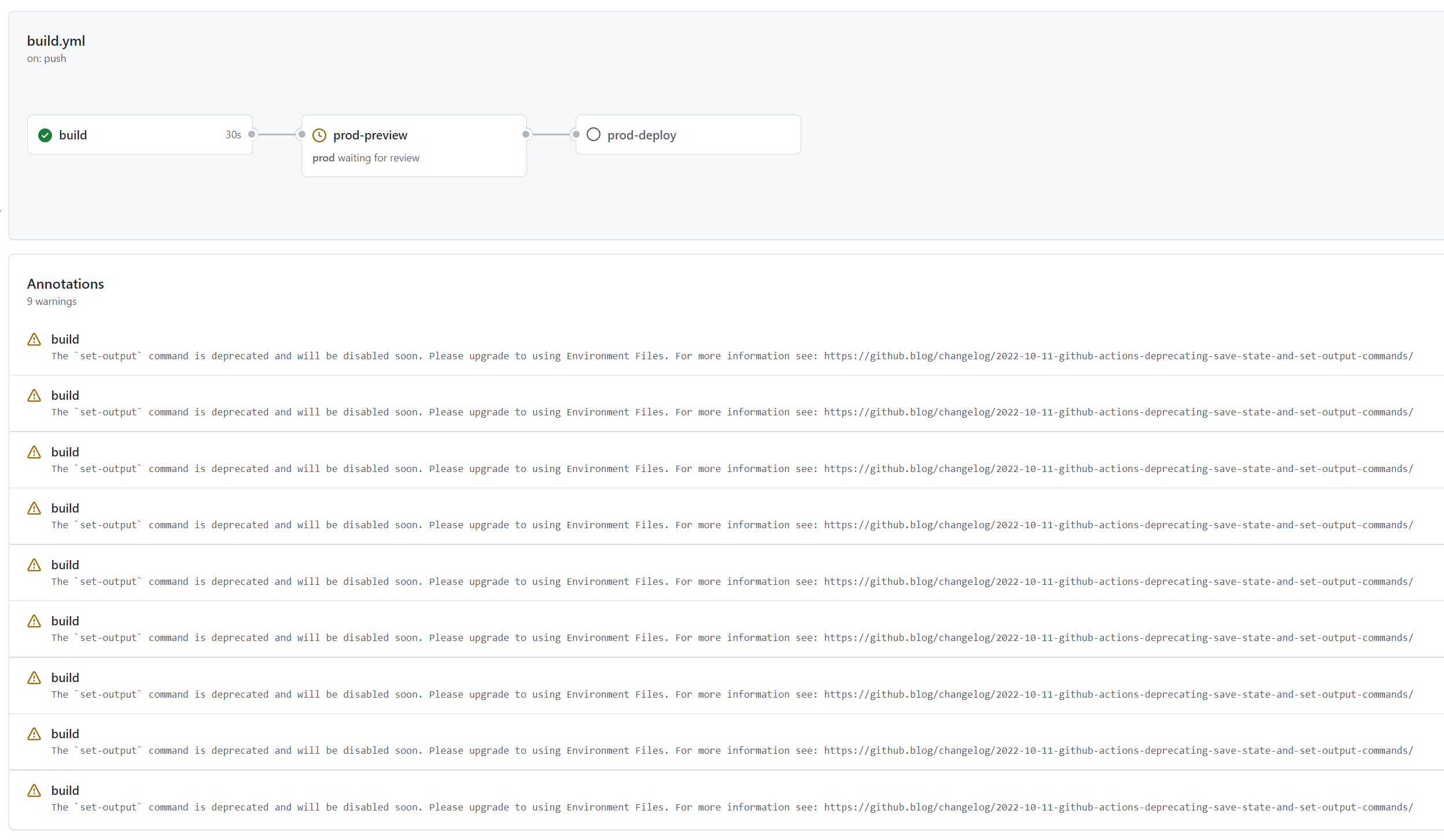
A typical build pipeline for us will include 3 stages.
The build step runs on a checkin trigger. This will run an initial build step which validates the terraform scripts are syntactically correct and well linted. A small number of our builds stop here. Unlike application deployments we typically want these changes to be live right away or at most during some maintenance window shortly after the changes have been authored. That deployments are run close to the time the changes were authored helps with our lack of rigour around code reviews.
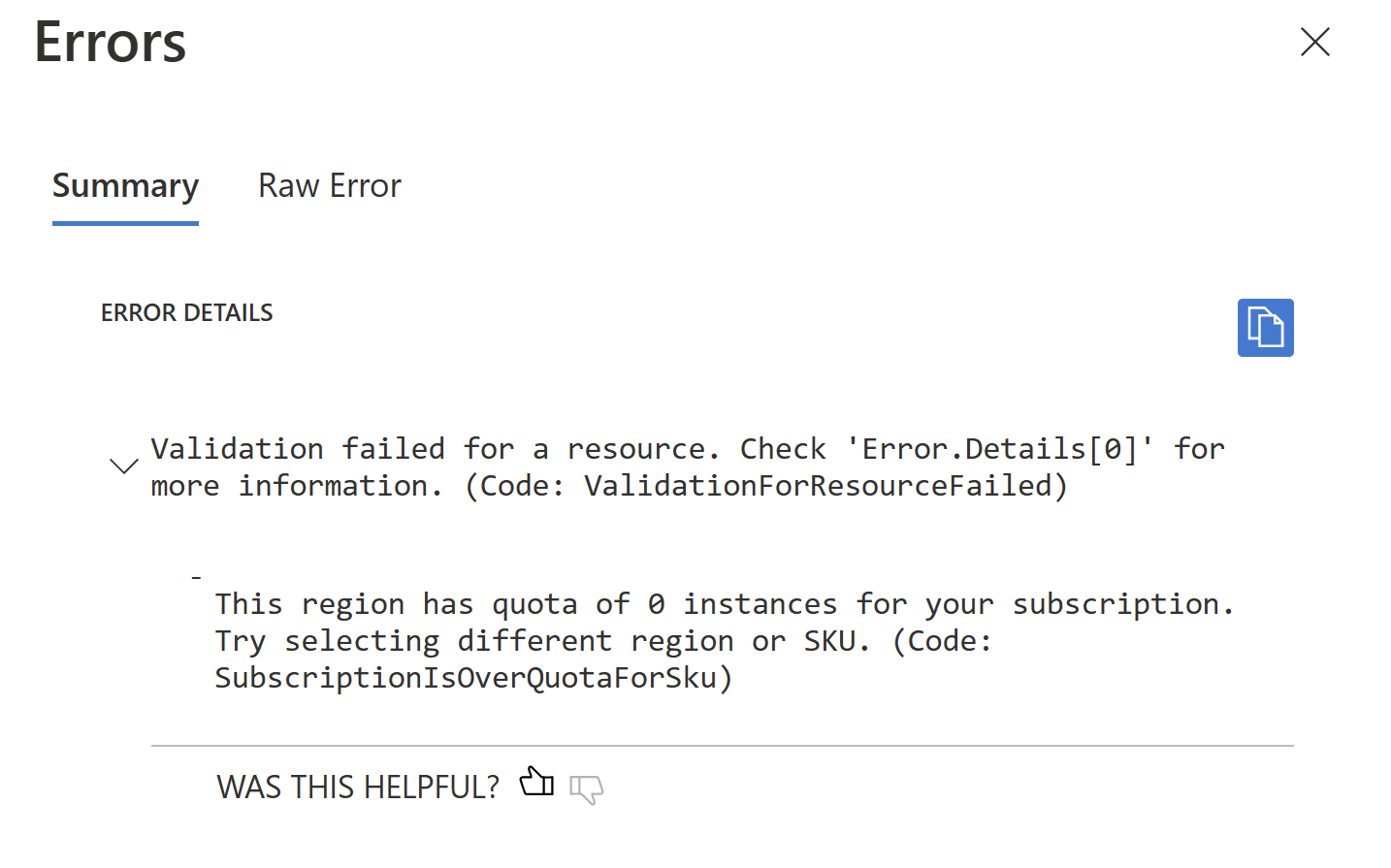
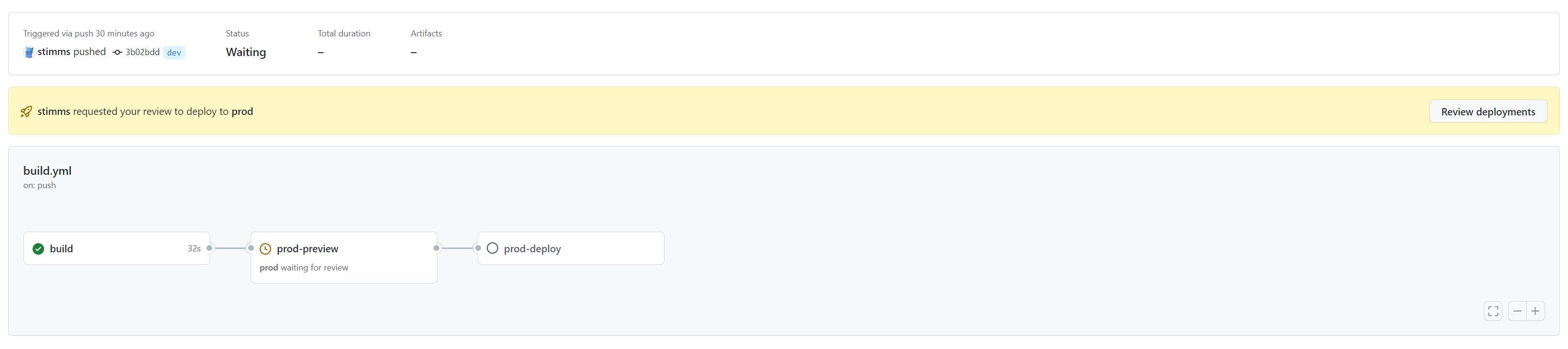
The next stage is to preview what changes will be performed by Terraform. This stage is gated such that it need somebody to actually approve it. It is low risk because no changes to made - we run a terraform plan and see what changes will be made. Reading over these changes is very helpful because we often catch unintended consequences here. Accidentally destroying and recreating a VM instead of renaming it? Caught here. Removing a tag that somebody manually applied to a resource and that should be preserved? Caught here.
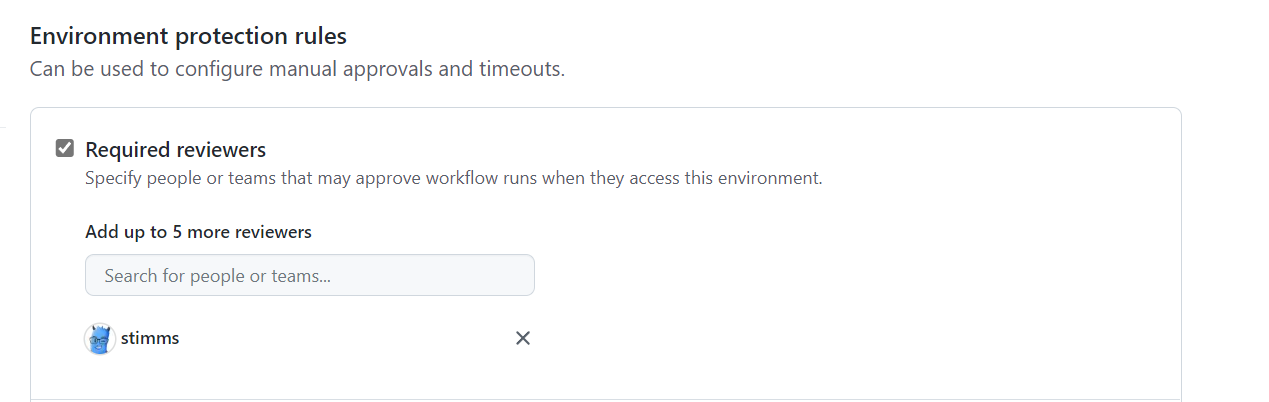
The final stage in the pipeline is to run the Terraform changes. This step is also gated to prevent us from deploying it without proper approvals. Depending on the environment we might need 2 approvals or at least one approval that isn’t the person writing the change. More eyes on a change will catch problems more easily and also socialize changes so that it isn’t a huge shock to the entire ops team that we now have a MySQL server in the enviornment or whatever it may be.
Most Azure resources support tagging. These are basically just labels that you can apply to resources. We use tags to help us organize our resources. We have a tag called environment which is used to indicate what environment the resource is in. We have a tag called owner which is used to indicate who owns the resource. We have a tag called project which is used to indicate what project the resource is associated with. But for these builds the most important tags are IaC Technology and IaC Source. The first is used to tell people that the resources are part of a Terraform deployment. The second is used to indicate where on GitHub the Terraform scripts are located. These tags make it really easy for people to find the Terraform scripts for a resource and get a change in place.

Permissions
I mentioned earlier that we like to guide ops people to make enviornment changes in Terraform rather than directly in Azure. One of the approaches we take around that is to not grant owner or writer permissions to resources directly to people be they ops or dev. Instead we have a number of permission restricted service principals that are used to make changes to resources. These service principals are granted permissions to specific resource groups and these service principals are what’s used in the pipeline to make the changes. This means that if somebody wants to make a change to a resource they need to go through the Terraform pipeline.
We keep the client id and secret in the secrets of the github pipeline
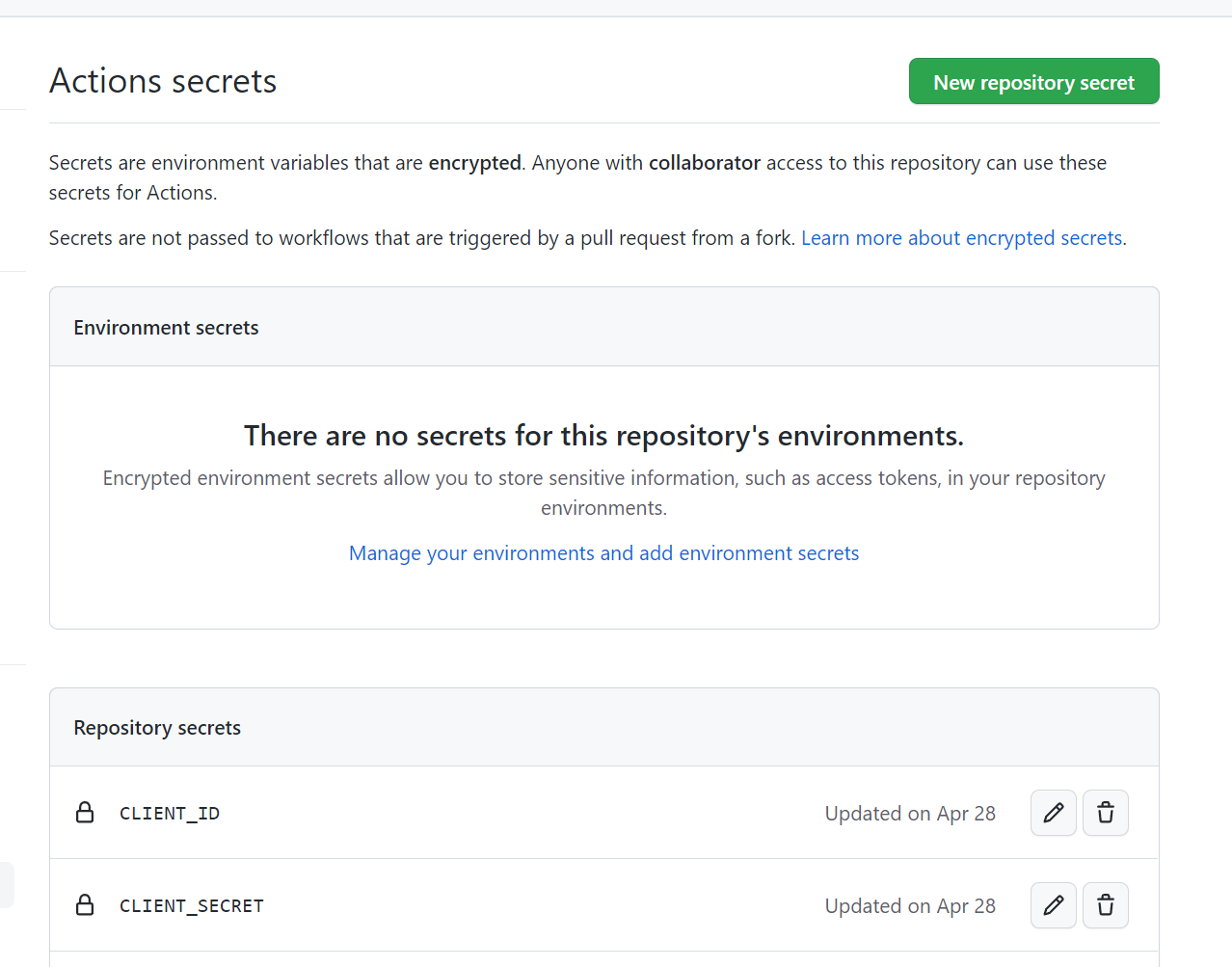
In this example we just keep a single repository wide key because we only have one enviornment. We’d make use of enviornment specific secrets if we had more than one environment.
This approach has the added bonus of providing rip stops in the event that we leak some keys somewhere. At worst that service principal has access only to one resource group so an attacker is limited to being able to mess with that group and not escape to the larger enviornment.
Achieving our Goals
To my mind this approach is exactly how IaC was meant to be used. We have a single source of truth for our infrastructure. We can make changes to that infrastructure in a repeatable way. We can review those changes before they are applied. All this while keeping the barrier to entry low for people who are not familiar with the code review process.
Future Steps
We already make use of Terraform modules for most of our deployment but we’re not doing a great job of reusing these modules from project to project. We’re hoping to keep a library of these modules around which can help up standardize things. For instance our VM module doesn’t just provision a VM - it sets up backups and uses a standardized source image.
I also really like the idea of using the build pipeline to annotate pull requests with the Terraform changes using https://github.com/marketplace/actions/terraform-pr-commenter. Surfacing this directly on the PR would save the reviewers the trouble of going through the pipeline to see what changes are being made. However it would be added friction for our ops team as they’d have to set up PRs.