In the previous article we looked at publishing messages and the one before that sending messages. But in both cases we cheated a little bit: we used the LearningTransport. This is effectively just a directory on disk. It cannot be used as real world transport. Let’s change out this transport for something more production ready.
Simon Online
NServiceBus Kata 2
In the previous kata we sent a message from one application to another. This is a common pattern in messaging systems. In this kata we’re going to look at a different pattern: publishing a message.
NServiceBus Kata 1
Exciting times for me, I get to help out on an NServiceBus project! It’s been way too long since I did anything with NServiceBus but I’m back, baby! Most of the team has never used NServiceBus before so I thought it would be a good idea to do a little kata to get them up to speed. I’ll probably do 2 or 3 of these and if they help my team they might as well help you, too.
- Kata 1 - Sending a message
- Kata 2 - Publishing a message
- Kata 3 - Switching transports
- Kata 4 - Long running processes
- Kata 5 - Timeouts
- Kata 6 - When things go wrong
The Problem
Our goal is to very simply demonstrate reliable messaging. If you’re communicating between two processes on different machines a usual approach is to send a message using HTTP. Problem is that sometimes the other end isn’t reachable. Could be that the service is down, could be that the network is down or it could be that the remote location was hit by a meteor. HTTP won’t help us in this case - what we want is a reliable protocol which will save the message somewhere safe and deliver it when the endpoint does show up.
For this we use a message queue. There are approximately 9 billion different messaging technologies out there but we’re going to use NServiceBus. NServiceBus is a .NET library which wraps up a lot of the complexity of messaging. It is built to be able to use a variety of transport such as RabbitMQ and Azure Service Bus.
We want to make use of NServiceBus and a few C# applications to demonstrate reliable messaging.
The Kata
I like cake but I feel bad about eating it because it’s not good for me. So in this kata you need to command me to eat cake. I can’t refuse a command to eat cake so I can’t possibly feel bad about it.
Create a sender application which sends a message to a receiver application. The receiver application should be able to receive the message and write it to the console. The sender application should be able to send the message and then exit. The receiver application should be able to start up and receive the message even if the sender application isn’t running.
Now go do it!
Useful resources:
My Solution
Create a new directory for the project
mkdir kata1 cd kata1Create a new console project for the sender
dotnet new console -o senderCreate a new console project for the receiver
dotnet new console -o receiverCreate a new class library for the messages
dotnet new classlib -o messagesAdd a reference to the messages project in the sender and receiver projects
dotnet add sender reference ../messages dotnet add receiver reference ../messagesAdd a reference to NServiceBus in all the projects
dotnet add sender package NServiceBus dotnet add receiver package NServiceBus dotnet add messages package NServiceBusCreate a new class in the messages project (and remove Class1.cs)
namespace messages;
using NServiceBus;
public class EatCake: ICommand
{
public int NumberOfCakes { get; set; }
public string Flavour { get; set; } = "Chocolate";
}
- Update Program.cs in the sender project to send a message
using messages;
using NServiceBus;
Console.Title = "NServiceBusKata - Sender";
var endpointConfiguration = new EndpointConfiguration("NServiceBusKataSender");
// Choose JSON to serialize and deserialize messages
endpointConfiguration.UseSerialization<SystemJsonSerializer>();
var transport = endpointConfiguration.UseTransport<LearningTransport>();
var endpointInstance = await Endpoint.Start(endpointConfiguration);
await endpointInstance.Send("NServiceBusKataReceiver", new EatCake{
Flavour = "Coconut",
NumberOfCakes = 2 //don't be greedy
});
await endpointInstance.Stop();
- Update Program.cs in the receiver project to be an endpoint
using NServiceBus;
Console.Title = "NServiceBusKata - Reciever";
var endpointConfiguration = new EndpointConfiguration("NServiceBusKataReceiver");
// Choose JSON to serialize and deserialize messages
endpointConfiguration.UseSerialization<SystemJsonSerializer>();
var transport = endpointConfiguration.UseTransport<LearningTransport>();
var endpointInstance = await Endpoint.Start(endpointConfiguration);
Console.WriteLine("Press Enter to exit...");
Console.ReadLine();
await endpointInstance.Stop();
- Add a message handler to the receiver project
using messages;
public class EatCakeHandler :
IHandleMessages<EatCake>
{
public Task Handle(EatCake message, IMessageHandlerContext context)
{
Console.WriteLine($"Cake eaten, NumberOfCakes = {message.NumberOfCakes}; Flavour = {message.Flavour}");
return Task.CompletedTask;
}
}
Things to try now:
- Run the sender project - it will send a message but the receiver won’t be running so nothing will happen
- Run the receiver project - it will start listening for messages and find the message which was left for it
- Run the sender project again - it will send a message and the receiver will pick it up and write to the console
This demonstrates reliable messaging with NServiceBus
Plinko Diagram
One of my team members mentioned that they envision the process flow of our code as a Plinko board. If you’ve never watched The Price is Right, a Plinko board is a vertical board with pegs that a contestant drops a disc down. The disc bounces off the pegs and lands in a slot at the bottom. The slots have different values and the contestant wins the value of the slot the disc lands in.

I just loved this mental model. Each peg in the board is an fork in the code and a different path can be taken from that point on. It’s basically an execution tree but with a fun visual that’s easy to explain to people.
flowchart TB
A --> B & C
B --> D & E
C --> F & G
Setting Container Cors Rules in Azure
This week I’m busy upgrading some legacy code to the latest version of the Azure SDKs. This code is so old it was using packages like WindowsAzure.Storage. Over the years this library has evolved significantly and is now part of the Azure.Storage.Blobs package. What this code I was updating was doing was setting the CORS rules on a blob container. These days I think I would solve this problem using Terraform and set the blob properties directly on the container. But since I was already in the code I figured I would just update it there.
So what we want is to allow anybody to link into these and download them with a GET
using Azure.Storage.Blobs;
using Azure.Storage.Blobs.Models;
...
var bsp = new BlobServiceProperties { HourMetrics = null, MinuteMetrics = null, Logging = null };
bsp.Cors.Add(new BlobCorsRule
{
AllowedHeaders = "*",
AllowedMethods = "GET",
AllowedOrigins = "*",
ExposedHeaders = "*",
MaxAgeInSeconds = 60 * 30 // 30 minutes
});
// from a nifty little T4 template
var connectionString = new ConnectionStrings().StorageConnectionString;
BlobServiceClient blobServiceClient = new BlobServiceClient(connectionString);
blobServiceClient.SetProperties(bsp);
Again, in hindsight I feel like these rules are overly permissive and I would probably want to lock them down a bit more.
Bypassing Formik Yup Validation
I’ve been using Formik with Yup validations for a while and it really a pretty good experience. The integration is tight and really all one needs to do is to define the validation schema and then pass it to Formik via the validationSchema. The validation is then run on every change to the form and the errors are displayed.
const schema = Yup.object().shape({
restricted: Yup.bool().required("Required"),
payer: Yup.string().required("Required"),
feeSchedule: Yup.string().required("Required")
...
});
return (
<Formik validationSchema={schema}
onSubmit={handleSubmit}
initialValues={{
restricted: false,
payer: "",
feeSchedule: ""
}}>
...
<FormikSubmitButton label="Save"/>
</Formik>
)
But today’s challenge was that we had a request to show validation errors but still submit the form. I have a custom submit button control I use which hooks into the Formik context and pulls out the submitForm and isValid properties. It then disables the button if the form isn’t valid. This means that I can have a really consistent look and feel to my forms’ submit buttons.
It looks a bit like this
const FormikSubmitButton = (props) => {
const { label, sx, disabled, ...restProps } = props;
const { submitForm, isValid } = useFormikContext();
const isDisabled = (!isValid || disabled);
return (
<>
<Button
disabled={isDisabled}
onClick={submitForm}
variant="contained"
color="primaryAction"
sx={sx}
{...restProps}
>
{label}
</Button>
</>
);
};
So the button disabled itself if the form isn’t valid. Now instead we need to bypass this so I passed in a new parameter allowInvalid which would allow the button to be clicked even if the form wasn’t valid.
const FormikSubmitButton = (props) => {
const { label, sx, disabled, allowInvalid, ...restProps } = props;
const { submitForm, isValid } = useFormikContext();
const isDisabled = (!isValid || disabled) && !allowInvalid;
return (
<>
<Button
disabled={isDisabled}
onClick={submitForm}
variant="contained"
color="primaryAction"
sx={sx}
{...restProps}
>
{label}
</Button>
</>
);
};
This fixes the button disabling itself but it doens’t resolve the issue of the form not submitting. The submitForm function from Formik will not submit the form if it is invalid. To get around this I had to call the handleSubmit function from the form and then manually set the form to be submitted. This is enough of a change that I wanted a whole separate component for it.
const FormikValidationlessSubmitButton = (props) => {
const { label, sx, disabled, onSubmit, ...restProps } = props;
const { setSubmitting, values } = useFormikContext();
const handleSubmit(){
setSubmitting(true);
if(onSubmit){
onSubmit(values);
}
setSubmitting(false);
}
return (
<>
<Button
disabled={disabled}
onClick={handleSubmit}
variant="contained"
color="primaryAction"
sx={sx}
{...restProps}
>
{label}
</Button>
</>
);
};
This component can then be used in place of the FormikSubmitButton when you want to bypass validation.
<Formik validationSchema={schema}
onSubmit={handleSubmit}
initialValues={{
restricted: false,
payer: "",
feeSchedule: ""
}}>
...
<FormikValidationlessSubmitButton onSubmit={handleSubmit} label="Save"/>
</Formik>
Docker COPY not Finding Files
My dad once told me that there are no such things a problems just solutions waiting to be applied. I don’t know what book he’d just read or course he’d just been on to spout such nonsense but I’ve never forgotten it.
Today my not problem was running a docker build wasn’t copying the files I was expecting it to. In particular I had a themes directory which was not ending up in the image and in fact the build was failing with something like
ERROR: failed to solve: failed to compute cache key: failed to calculate checksum of ref b1f3faa4-fdeb-41ed-b016-fac3862d370a::pjh3jwhj2huqmcgigjh9udlh2: "/themes": not found
I was really confused because themes absolutly did exist on disk. It was as if it wasn’t being added to the build context. In fact it wasn’t being added and, as it turns out, this was because my .dockerignore file contained
**
Which ignores everything from the local directory. That seemed a bit extreme so I changed it to
**
!themes
With this in place the build worked as expected.
Connect to a Service Container in Github Actions
Increasingly there is a need to run containers during a github action build to run realistic tests. In my specific scenario I had a database integration test that I wanted to run against a postgres database with our latest database migrations applied.
We run our builds inside a multi-stage docker build so we actually need to have a build container communicate with the database container during the build phase. This is easy enough in the run phase but in the build phase there is just a flag you can pass to the build called network which takes an argument but the arguments it can take don’t appear to be documented anywhere. After significant trial and error I found that the argument it takes that we want is host. This will build the container using the host networking. As we surfaced the ports for postgres in our workflow file like so
postgres:
image: postgres:15.3
ports:
- 5432:5432
env:
POSTGRES_DB: default
POSTGRES_USER: webapp_user
POSTGRES_PASSWORD: password
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
We are able to access the database from the build context with 127.0.0.1. So we can pass in a variable to our container build
docker build --network=host . --tag ${{ env.DOCKER_REGISTRY_NAME }}/${{ env.DOCKER_IMAGE_NAME }}:${{ github.run_number }} --build-arg 'DATABASE_CONNECTION_STRING=${{ env.DATABASE_CONNECTION_STRING }}'
With all this in place the tests run nicely in the container during the build. Phew.
Setting up SMTP for Keycloak Using Mailgun
Quick entry here about setting up Mailgun as the email provider in Keycloak. To do this first you’ll need to create SMTP credentials in Mailgun and note the generated password
Next in Keycloak set the credentials up in the realm settings under email. You’ll want the host to be smtp.mailgun.org and the port to be 465. Enable all the encryptions and use the full email address as the username.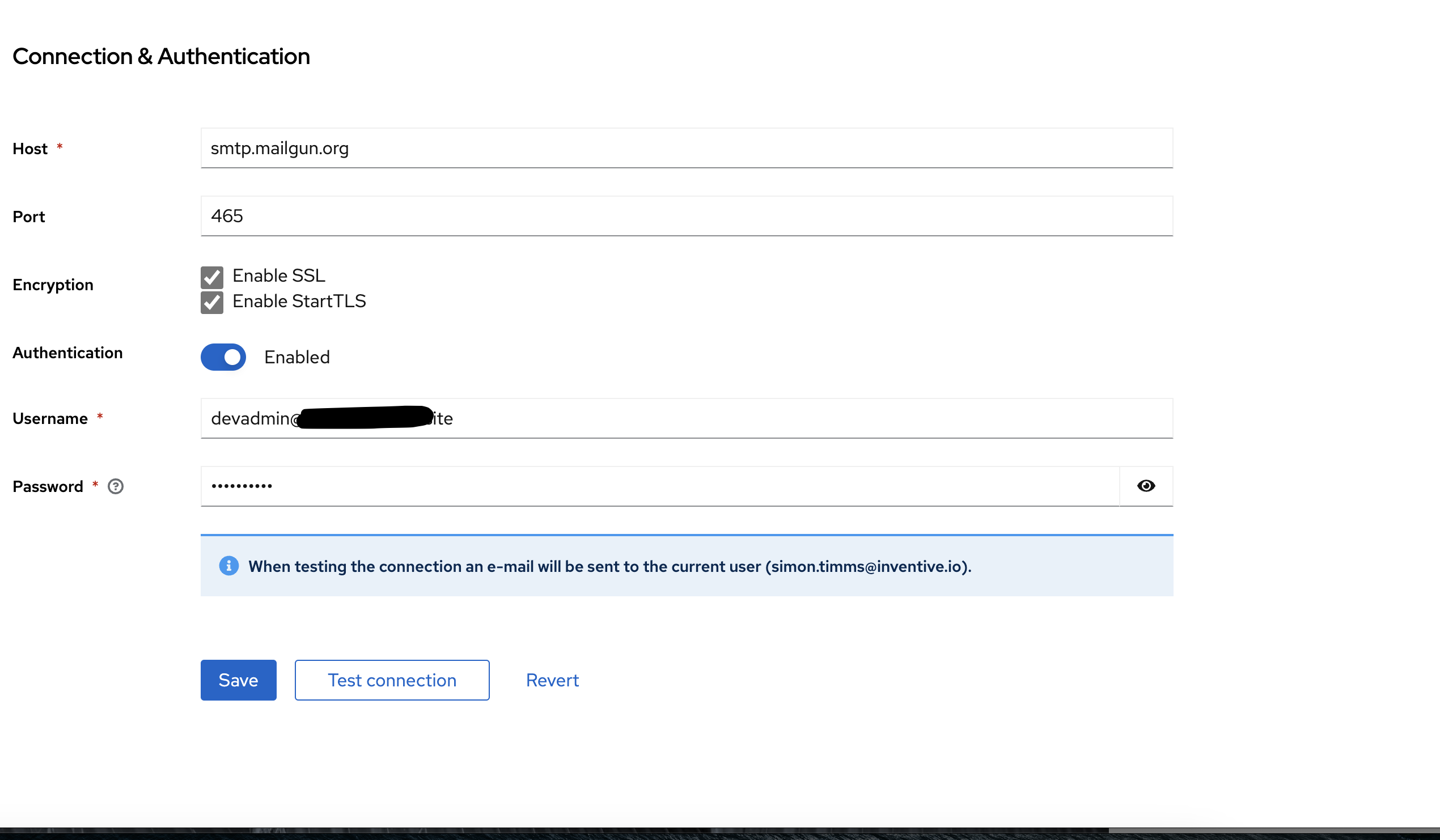
Check both the SSL boxes and give it port 465.
Load Testing with Artillery
Load testing a site or an API can be a bit involved. There are lots of things to consider like what the traffic on your site typically looks like, what peaks look like and so forth. That’s mostly outside the scope of this article which is just about load testing with artillery.
Scenario
We have an API that we call which is super slow and super fragile. We were recently told by the team that maintains it that they’d made improvements and increased our rate limit from something like 200 requests per minute to 300 and could we test it. So sure, I guess we can do your job for you. For this we’re going to use the load testing tool artillery.
Getting started
Artillery is a node based tool so you’ll need to have node installed. You can install artillery with npm install -g artillery.
You then write a configuration file to tell artillery what to do. Here’s the one I used for this test (with the names of the guilty redacted):
config:
target: https://some.company.com
phases:
- duration: 1
arrivalRate: 1
http:
timeout: 100
scenarios:
- flow:
- log: "Adding new user
- post:
url: /2020-04/graphql
body: |
{"query":"query readAllEmployees($limit: Int!, $cursor: String, $statusFilter: [String!]!) {\n company {\n employees(filter: {status: {in: $statusFilter}}, pagination: {first: $limit, after: $cursor}) {\n pageInfo {\n hasNextPage\n startCursor\n endCursor\n hasPreviousPage\n }\n nodes {\n id\n firstName\n lastName\n\t\tmiddleName\n birthDate\n displayName\n employmentDetail {\n employmentStatus\n hireDate\n terminationDate\n }\n taxIdentifiers {\n taxIdentifierType\n value\n }\n payrollProfile {\n preferredAddress {\n streetAddress1\n streetAddress2\n city\n zipCode\n county\n state\n country\n }\n preferredEmail\n preferredPhone\n compensations {\n id\n timeWorked {\n unit\n value\n }\n active\n amount\n multiplier\n employerCompensation {\n id\n name\n active\n amount\n timeWorked {\n unit\n value\n }\n multiplier\n }\n }\n }\n }\n }\n }\n}\n","variables":{
"limit": 100,
"cursor": null,
"statusFilter": [
"ACTIVE",
"TERMINATED",
"NOTONPAYROLL",
"UNPAIDLEAVE",
"PAIDLEAVE"
]
}}
headers:
Content-Type: application/json
Authorization: Bearer <redacted>
As you can see this is graphql and it is a private API so we need to pass in a bearer token. The body I just stole from our postman collection so it isn’t well formatted.
Running this is as simple as running artillery run <filename>.
At the top you can see arrival rates and duration. This is saying that we want to ramp up to 1 requests per second over the course of 1 second. So basically this is just proving that our request works. The first time I ran this I only got back 400 errors. To get the body of the response to allow me to see why I was getting a 400 I set
export DEBUG=http,http:capture,http:response
Once I had the simple case working I was able to increase the rates to higher levels. To do this I ended up adjusting the phases to look like
phases:
- duration: 30
arrivalRate: 30
maxVusers: 150
This provisions 30 users a second up to a maximum of 150 users - so that takes about 5 seconds to saturate. I left the duration higher because I’m lazy and artillery is smart enough to not provision more. Then to ensure that I was pretty constantly hitting the API with the maximum number of users I added a loop to the scenario like so:
scenarios:
- flow:
- log: "New virtual user running"
- loop:
- post:
url: /2020-04/graphql
body: |
{"query":"query readAllEmployeePensions($limit: Int!, $cursor: String, $statusFilter: [String!]!) {\n company {\n employees(filter: {status: { in: $statusFilter }}, pagination: {first: $limit, after: $cursor}) {\n pageInfo {\n hasNextPage\n startCursor\n endCursor\n hasPreviousPage\n }\n nodes {\n id\n displayName\n payrollProfile {\n pensions {\n id\n active\n employeeSetup {\n amount {\n percentage\n value\n }\n cappings {\n amount\n timeInterval\n }\n }\n employerSetup {\n amount {\n percentage\n value\n }\n cappings {\n amount\n timeInterval\n }\n }\n employerPension {\n id\n name\n statutoryPensionPolicy\n }\n customFields {\n name\n value\n }\n }\n }\n }\n }\n }\n}\n","variables":{
"limit": 100,
"statusFilter": [
"ACTIVE"
]
}}
headers:
Content-Type: application/json
Authorization: Bearer <redacted>
count: 100
Pay attention to that count at the bottom.
I was able to use this to fire thousands of requests at the service and prove out that our rate limit was indeed higher than it was before and we could raise our concurrency.