Machine Learning for Boring Applications
C# Advent
This post is one among many which is part of 2019’s C# Advent. There are a ton of really great posts this year and some new bloggers to discover. I’d strongly encourage you to check it out.If you read at all about the myriad of applications for machine learning you’ll find that there are a lot of people out there building really cool stuff. Cars which drive themselves. Things which write tweets based on an AI’s interpretation of thousands of tweets about venture capitalists. Unfortunately I, like a lot of developers, earn our bread and butter by writing what is mostly boring forms over data applications. This is a space in which there is 0 application for machine learning. Or is there?
In this post, and maybe others in the future, I’ll look at how we can apply a little bit of AI/ML to boring old forms over data to improve the user experience.
Suggestion Box
A very common pattern in form design is to have a series of select boxes, each one driven by the previous suggestion. It is a great way to make the selecting of hierarchical data easier. Some examples might be selecting a country first, then a state or province. Selecting a period then an element from the periodic table. Really there are countless examples. Typically we order the contents of these boxes alphabetically but that might not be the most efficient for people.
Imagine you live in the United States of America and need to select your address. First you select your country then the state from a second drop down. But if you look at a list of the states alphabetically you’ll see
- Alabama
- Alaska
- American Samoa
- Arizona
- Arkansas
- …
Well those are all fine states (and territories) but all together they have only 16 million people. The next entry on that list, California, has 39 million people. In fact if you keep adding up entries you need to get all the way to Florida before you have a total that exceeds California. And Texas? 29 million people, that’s way down there. So perhaps it would make sense to pull some of those highly populated areas up to the top of the list.
But perhaps your application is more commonly used in New Jersey in which case that could be higher on the list. Instead of guessing you could plug the data quickly into a learning algorithm and have it provide some suggestions. Now the math to find the most likely to be selected value based on a single criteria is easy - doesn’t really necessitate what I’d call AI. So let’s make it a bit more complex by having a combination of two fields drive the ordering of a third. You can do this using statistics but really with the simplicity of ML libraries now why not make use of them?
ML.NET
We’re going to make use of ML.NET for this. If you haven’t played with ML.NET yet I’d encourage you to try it out - you’re here reading this so that’s a start!
I’m going to take a second here to put in a warning. I wrote this article using one algorithm and now I’ve thought about it a bit it is absolutely the wrong algorithm. It gives the right answer on my test data but in the real world it wouldn’t. I’ll revisit this and explain why it is wrong in a future article.
First thing is to create the data container classes for our loaded data.
public class PredictiveModel
{
[LoadColumn(0)] public int CountryId { get; set; }
[LoadColumn(1)] public int ColorId { get; set; }
[LoadColumn(2)] public Single PetId { get; set; }
}
public class Prediction
{
public Single PetId { get; set; }
public Single Score { get; set; }
}
This data is going to be loaded from a CSV file for this example but you could take it from a database.
var context = new MLContext();
// load the dataset
var data = context.Data.LoadFromTextFile<PredictiveModel>(
Path.Combine(Environment.CurrentDirectory, "value.csv"),
hasHeader: true,
separatorChar: ',');
// split the data into and 80:20 training and testing set
var partitions = context.Data.TrainTestSplit(data, testFraction: 0.2);
Now to build the actual model
IEstimator<ITransformer> estimator = context.Transforms.Conversion
.MapValueToKey(outputColumnName: "countryIdEncoded", inputColumnName: "CountryId")
.Append(context.Transforms.Conversion.MapValueToKey(outputColumnName: "colorIdEncoded", inputColumnName: "ColorId"));
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "countryIdEncoded",
MatrixRowIndexColumnName = "colorIdEncoded",
LabelColumnName = "PetId",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(context.Recommendation().Trainers.MatrixFactorization(options));
ITransformer model = trainerEstimator.Fit(partitions.TrainSet);
Here we’ve used a matrix factorization training which takes in two predictive dimensions and predicts the output at the intersection of those. (Keep in mind that this is the wrong approach). From this we then create a prediction engine
var predictionEngine = context.Model.CreatePredictionEngine<PredictiveModel, Prediction>(model);
I registered this model in the DI container in my ASP.NET Core application
public void ConfigureServices(IServiceCollection services)
{
...
services.AddSingleton<PredictionEngine<PredictiveModel, Prediction>>(new ModelBuilder().Build());
}
This does have an impact on the startup because we rebuild the model on each start. In a real world situation we’d probably want to build the model offline and then load it in the main application.
In our API controller we return the list and the most likely candidate.
[Route("/api/pets")]
public IActionResult Index(int countryId, int colorId)
{
var prediction = engine.Predict(new PredictiveModel { CountryId = countryId, ColorId = countryId, PetId = 1 });
var pets = new List<string> {
"Cat",
"Dog",
"Monkey",
"Bat",
"Gerbil",
"Graboid"
};
return new JsonResult(new { items = pets, predicted = Math.Round(prediction.Score) });
}
This allows us to build a screen that looks like this:
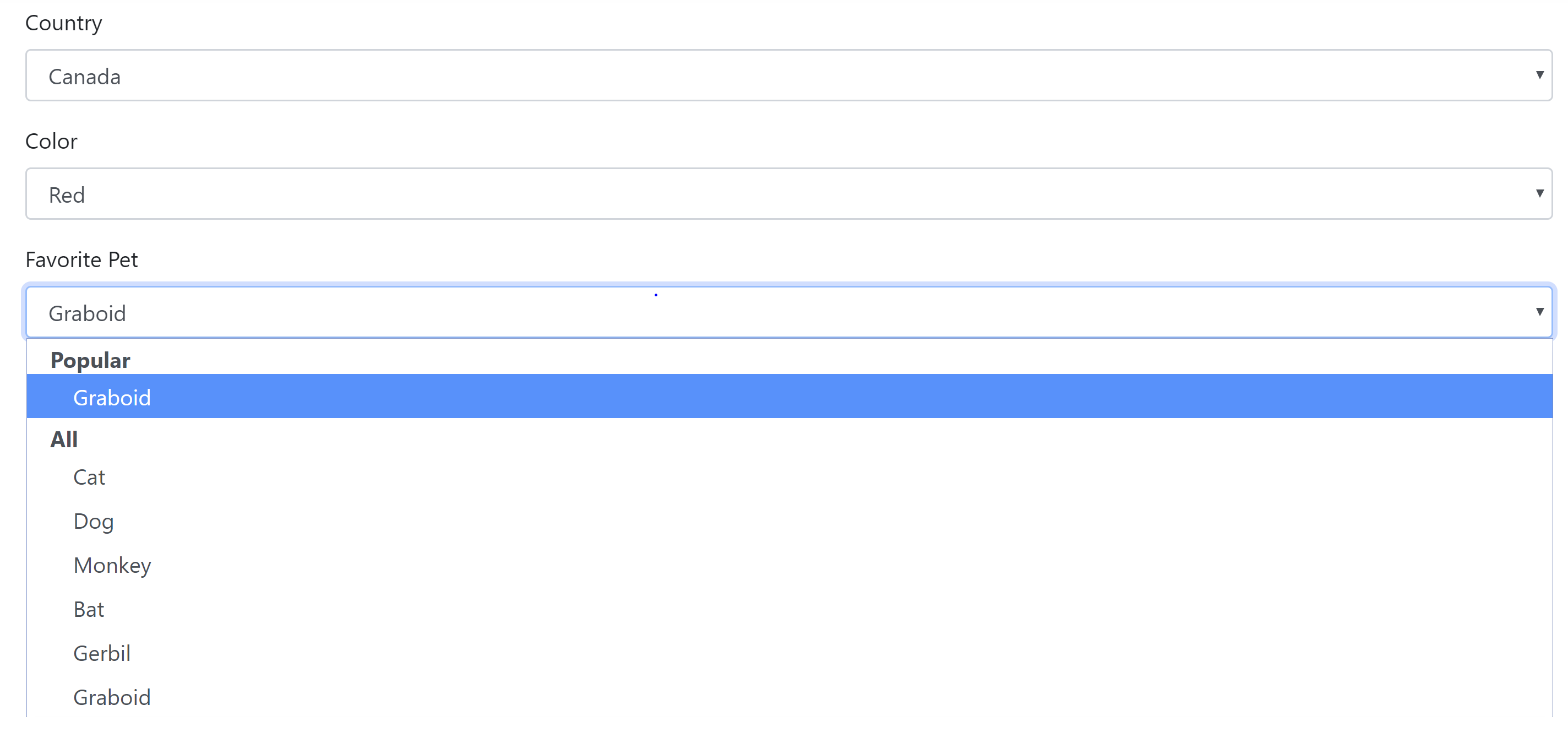
So even in a pretty boring app we can improve the user experience by using a little bit of AI.